By: Courtney Turrin
Published Date: April 13, 2026
Most brands entering AI search optimization start with the same assumption: if my content is relevant and authoritative, AI platforms will cite it. It’s a reasonable assumption. It’s also wrong — or at least, incomplete in ways that matter enormously.
The missing piece is what we call the Semantic Centroid Distance Principle. It explains, in precise terms, why two pieces of content covering the same topic at similar quality levels can produce dramatically different citation rates across ChatGPT, Claude, Perplexity, and Gemini. And once you understand the mechanism, the implications for how content needs to be written and structured become hard to ignore.
Contents
The Model: A Multi-Dimensional Semantic Vector Space
When a large language model receives a query, it doesn’t search for the most relevant document in a straightforward sense. It translates both the query and every piece of retrieved content into vectors — coordinates in a multi-dimensional mathematical space where position encodes meaning.
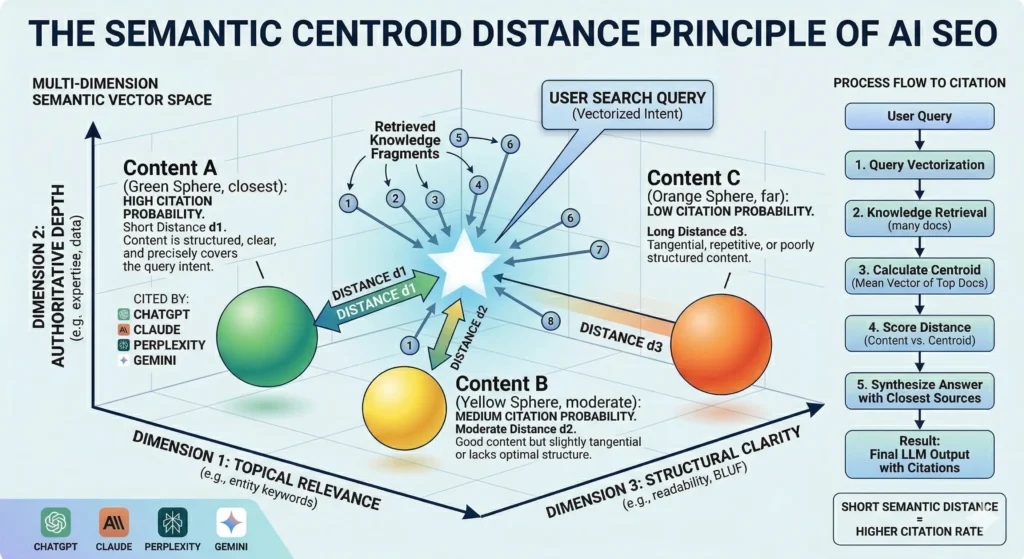
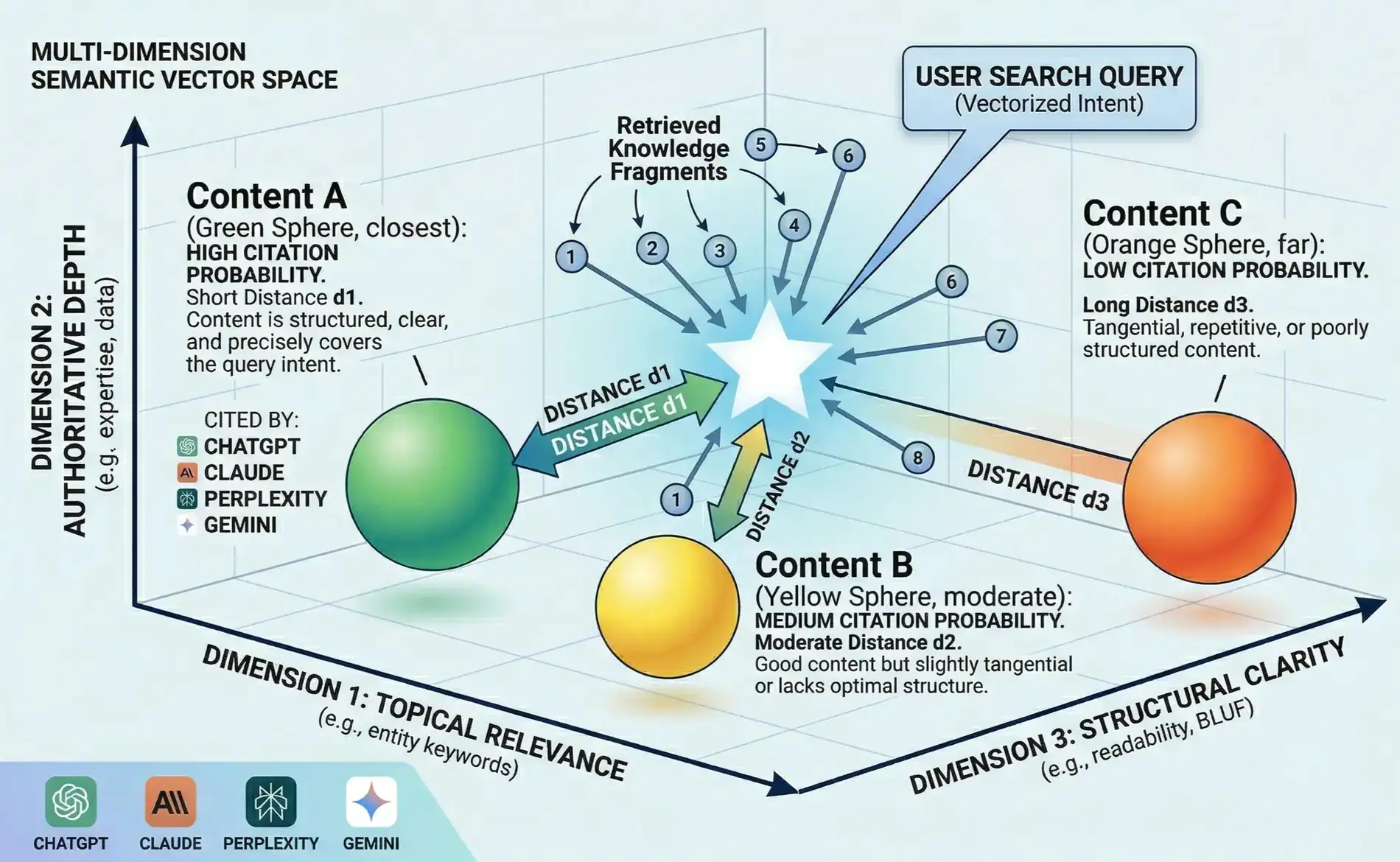
The diagram above shows a simplified version of this space rendered across three dimensions: Topical Relevance, Authoritative Depth, and Structural Clarity. In practice, the space has far more dimensions — but these three capture the essential axes that determine citation outcomes.
In this space, every retrieved document has a position. So does the query itself. And so does something the model constructs dynamically: the semantic centroid.
What Is the Semantic Centroid?
When an LLM retrieves a set of highly relevant documents to answer a query, it effectively calculates the statistical mean of those documents’ vectors — the mathematical center of the retrieved knowledge cluster. This centroid represents the idealized consensus answer: the position in semantic space that best synthesizes what the collective set of top retrieved content is saying.
This is the target. Not the query. The centroid.
The model then measures how close each individual piece of content is to that centroid. Content with a short semantic distance — positioned close to the consensus center — earns citations at measurably higher rates. Content with a long semantic distance gets deprioritized, regardless of how authoritative or relevant it might be in isolation.
We validated this relationship at a Spearman correlation of 0.976 across more than 156,000 prompt-brand citation pairs across four large language models. For context, a correlation above 0.9 is considered exceptional in social science research. This is not a directional signal — it is a finding. It is also one of several hypotheses under active investigation at CARL Lab.
The Three Citation Outcomes (and Why They Happen)
The diagram illustrates three content positions and their citation outcomes:
- Content A (short distance d1) — high citation probability. This content is structured, clear, and precisely covers the query intent across all three semantic dimensions. It sits close to the star — the centroid — because it aligns with the consensus of top retrieved documents. ChatGPT, Claude, Perplexity, and Gemini all cite it consistently.
- Content B (moderate distance d2) — medium citation probability. The content itself is good — substantive, factual, reasonably well structured. But it’s slightly tangential, or it lacks the structural clarity that pulls it toward the centroid. It earns citations sometimes, not reliably.
- Content C (long distance d3) — low citation probability. This content may be accurate and even authoritative. But it’s tangential, repetitive, or poorly structured in ways that push it away from the semantic center. The model sees it as a weaker representative of the idealized answer and passes over it.
The distinction between A and C is not about quality in the traditional sense. It’s about position relative to consensus.
The Five-Step Process from Query to Citation
The right side of the diagram maps the process flow that produces these outcomes:
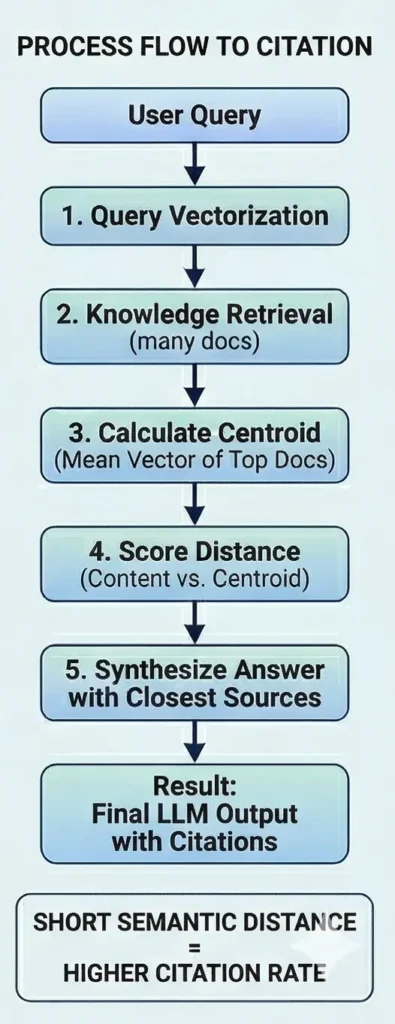
- Query vectorization. The user’s search intent is translated into a vector that locates the query in semantic space.
- Knowledge retrieval. The system pulls many documents identified as highly relevant to the query vector.
- Centroid calculation. The system computes the mean vector of the top retrieved documents — the consensus ideal answer.
- Distance scoring. Each document is scored by its proximity to the centroid.
- Answer synthesis. The model builds its response using the closest sources, producing the final output with citations.
The implication: content isn’t evaluated in isolation. It’s evaluated relative to what else exists. The centroid shifts as the competitive set shifts. A piece of content that earns strong citations today can lose ground as new content enters the space — not because it degraded, but because the consensus moved.
Key Concepts at a Glance
A few terms worth knowing before the table:
- Semantic vector space. A mathematical model that translates text into coordinates. Words, phrases, and entire documents are assigned positions in this space based on meaning — not keywords. Content that means similar things sits close together; content that diverges sits far apart.
- Vector embedding. The process of converting a piece of text into its coordinates in the semantic vector space. When an LLM receives a query or retrieves a document, it embeds both — turning language into a position it can measure and compare.
- Semantic centroid. The mathematical center of a cluster of retrieved documents. When an LLM pulls a set of highly relevant results for a query, the centroid is the average position of all those results — the point in semantic space that best represents what the collective retrieved knowledge is saying.
- Semantic distance. The measurable gap between two positions in the vector space. Short semantic distance means two pieces of content are conceptually close. Long semantic distance means they diverge — even if they cover the same topic.
- Cosine similarity. The specific metric most LLMs use to calculate semantic distance. Rather than measuring straight-line distance between two vectors, it measures the angle between them — which is more stable across documents of different lengths and structures.
These are the building blocks of the framework the table below maps out.
| Concept | What It Means | Why It Matters for AI SEO |
|---|---|---|
| Semantic vector space | A multi-dimensional coordinate system where meaning is represented by position | All content and queries are translated into coordinates — proximity to others is measurable |
| Query embedding | The user’s input translated into a vector | Defines the starting area of semantic search |
| Retrieved knowledge | Multiple documents pulled as highly relevant to the query | The context pool from which the LLM synthesizes its answer |
| Semantic centroid | The statistical mean of the top retrieved knowledge fragments | This is the target — the closer your content is to it, the higher your citation rate |
| Short semantic distance | High similarity to the consensus ideal answer | Results in high citation rate |
| Long semantic distance | Low similarity — tangential, divergent terminology, or poor structure | Results in low citation rate, even for accurate content |
What This Means for Content Strategy
Understanding the Semantic Centroid Distance Principle reframes several common content strategy questions.
“Should I differentiate my content?”
Differentiation in traditional SEO — taking a contrarian angle, covering a niche sub-topic — can actively increase semantic distance. Content that diverges from consensus, even intelligently, moves away from the centroid. That doesn’t mean differentiation is always wrong, but it needs to be deliberate, with an understanding that it trades citation probability for other strategic goals.
“Does more content help?”
Volume alone doesn’t help — and can hurt if it introduces semantic noise around a topic. What matters is whether each piece of content is positioned close to the centroid for its target query cluster. A single well-positioned piece outperforms ten tangential ones.
“Does my content structure matter that much?”
Yes, significantly. Structural Clarity is one of the three dimensions in the vector space for a reason. Content that covers the right topic with the right depth but presents it in ways that are hard to parse — dense paragraphs, buried answers, poor information hierarchy — increases semantic distance. The model has difficulty locating the relevant signal, and the content drifts from the centroid even when the substance is correct.
“How often do I need to update content?”
The centroid is not static. As new content enters a query cluster, as platforms update their retrieval models, as query behavior shifts, the consensus center moves. Content that earned strong citations can lose ground without any change on your end. Monitoring citation performance over time — not just at publication — is a structural requirement of AI search optimization, not a nice-to-have.
The Centroid as a Research Target
At CARL Lab, the Semantic Centroid Distance finding is one validated hypothesis within a larger research program. The practical output of that research is the ability to model where the centroid sits for a given query cluster before publishing — and to engineer content that minimizes distance from it from the start.
That’s a different kind of content work than most agencies are doing. It requires the research infrastructure to track citation patterns at scale, the data to model centroid positions across industries and query types, and an operational model that can translate those findings into published content quickly enough to matter.
The Semantic Centroid Distance Principle is one validated hypothesis within a larger body of research. The CARL Model incorporates it alongside other principles still under investigation — because AI search is not a solved problem, and any framework that claims otherwise isn’t doing the work.
The CARL Model is the research and operational framework that Xponent21 uses to run AI search optimization.

Courtney Turrin
As the company’s number two employee, Courtney has helped guide the direction of our business, build a powerhouse team, and implement technology and workflows to improve service delivery and produce outsized results for our clients. Her current role sits at the intersection of analytics, work management, and operations. Drawing on her background in scientific research, Courtney designs efficient processes and supports our teams so they can better serve our clients. She holds masters degrees in Biology and Psychology/Neuroscience from the College of William and Mary and Yale University, respectively. Offline, Courtney is a plant whisperer, Peloton enthusiast, and proud pet mom.