By: Isaac Marcuson

Published Date: July 2, 2026
Modified Date: July 16, 2026
TL;DR: The standard Claude optimization playbook rests on 15 launch-day data points. The core claim holds: Claude’s web search runs on Brave. But Anthropic’s own subprocessor list names a second web-search provider, turbopuffer, that almost no one has reported. And “ignore Google” gets crawl access exactly backwards.
Contents
- The 86.7% Claude-to-Brave Overlap Is Built on 15 Data Points
- Claude’s Web Search Runs on Brave, Verified at the Source
- Why “Ignore Google” Is Backwards on Access and Overstated on Rank
- The Second Subprocessor Everyone Missed: turbopuffer
- Dynamic Filtering Is Real, and “No Re-Ranking” Is Contested
- How Claude Cites Differently From ChatGPT and Gemini
- Every GEO Stat Is Vendor-Shaped, Including Ours
- The Three Levers of AI Visibility: Memory, Retrieval, Extractability
- The Corrected Claude Playbook
- The Bottom Line on Optimizing for Claude
- FAQ
The 86.7% Claude-to-Brave Overlap Is Built on 15 Data Points
Nearly every “how to optimize for Claude” post you’ve read traces back to one figure: 86.7% overlap between Claude’s web citations and the top results on Brave, an independent search engine with its own index, separate from Google’s or Bing’s. I went looking for where that figure came from.
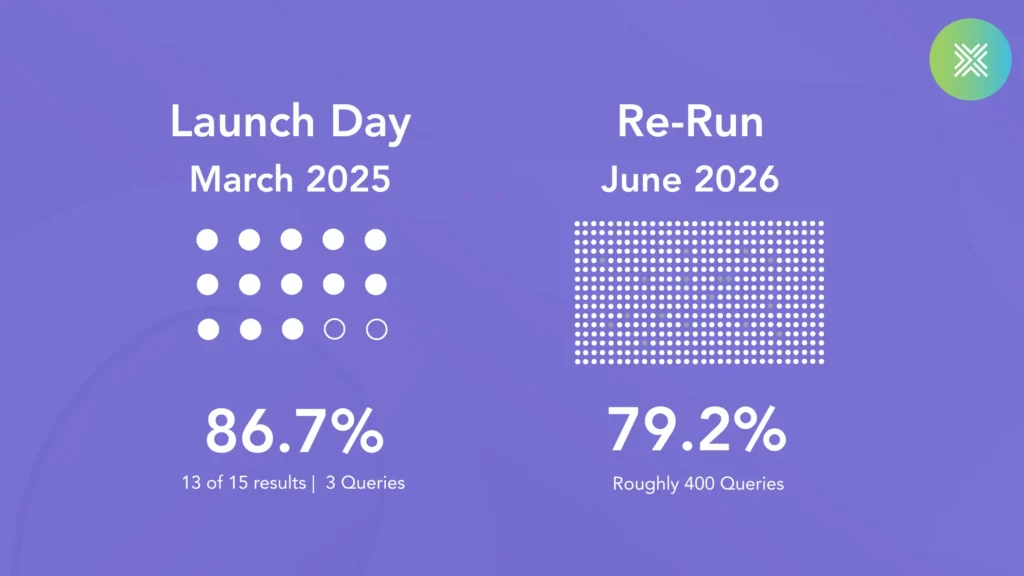
It comes from a single vendor blog post, published March 21, 2025, one day after Claude’s web search launched. The 86.7% is 13 matches out of 15 results across three commercial “best X” queries.
The result is real. Three queries, on day one, from one vendor. The launch-day number just carries more weight than 15 data points can hold.
Profound itself finally re-ran the test in June 2026, on a sample reported at roughly 400 queries, and got 79.2% — 7.5 points lower on a far larger sample size. That level means roughly one in five of Claude’s citations comes from somewhere other than Brave’s top 10.
The advice built on the launch-day figure has hardened into a playbook, and parts of it point in the wrong direction.
Claude’s Web Search Runs on Brave, Verified at the Source
Brave is a confirmed, current backend for Claude’s text search. Anthropic added Brave Search to its subprocessor list on March 19, 2025. Simon Willison replicated the behavior the same week, a rare independent check in this genre, finding citations that matched Brave’s results and Brave-specific parameters exposed in the search function. We checked the list ourselves, most recently on July 2, 2026, and Brave is still there, scoped to all products. The dependency is live.
Brave also matters more now than when the 86.7% figure was published. Microsoft retired the public Bing Search API in August 2025. Google’s Custom Search JSON API is capped at 10,000 queries per day, closed to new customers, and scheduled for retirement on January 1, 2027. That leaves Brave as one of the few independent Western search indexes operating at scale.
Why “Ignore Google” Is Backwards on Access and Overstated on Rank
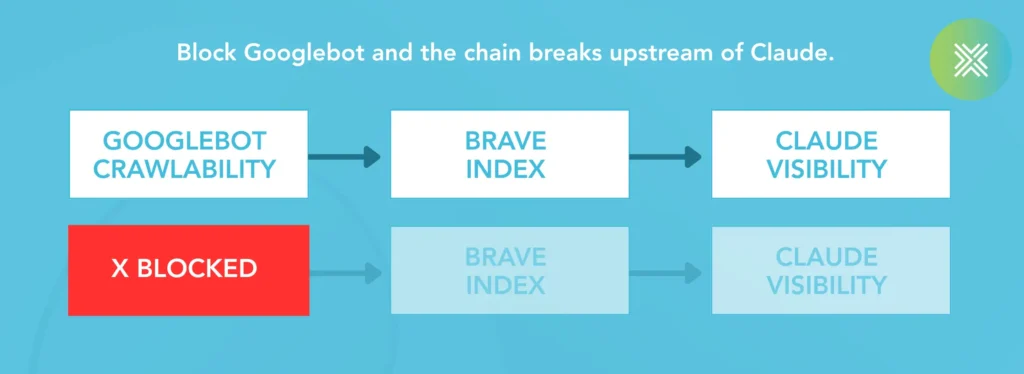
The most repeated piece of advice in the Generative Engine Optimization (GEO) space is some version of “your Google ranking barely matters for Claude.” Split that claim in two, because its halves fail in different ways. On crawl access, it’s fully backwards, and Brave’s own documentation proves the dependency. On rank, it’s overstated.
Brave’s crawler page states two things plainly. First, Brave’s bot uses no differentiated user agent. Second, and decisively: if a page is not crawlable by Googlebot, Brave’s bot will not crawl it either. Googlebot crawlability is a prerequisite for Brave indexing, and Brave indexing is a prerequisite for Claude’s web-search visibility. You cannot abandon Google access and expect to show up in Claude.
Recent Profound data shows 64% of Claude’s cited URLs appear somewhere in Google’s top 50 for the same query, but only 34% appear in Google’s top 10. That correlation is loose. Rank travels with Claude visibility, but no strict pipeline runs from a Google position to a Claude citation. And Claude’s citations overlap ChatGPT’s a mere 8% of the time. Google SEO carries over to Claude in a way ChatGPT tactics do not.
Google access is table stakes. Rank helps at the margin. Brave is the differentiator stacked on top.
The Second Subprocessor Everyone Missed: turbopuffer
The same Anthropic subprocessor list that confirms Brave also shows a second entry categorized under “Web Search”: turbopuffer, a vector and full-text search database built by former Shopify engineers for AI and retrieval use. Anthropic’s Trust Center states in its own words that turbopuffer provides web search for all Anthropic products except Claude for Government. The Trust Center dates the addition to May 6, 2026, nearly fourteen months after Brave.
On the live list, the Brave and turbopuffer entries link to the same Anthropic support article on enabling and using web search. And turbopuffer itself publicly lists Anthropic as a customer, while publishing nothing about the use case.
The fact: Anthropic classifies a vector/full-text search database as a “Web Search” subprocessor, sitting next to Brave’s keyword index.
The inference: we cannot confirm from public sources exactly how that component is used. It could cache and index web content for semantic retrieval, sit as a retrieval layer over candidate results, support a related feature — or play no role in which sources get cited at all.

The listing alone unsettles the genre’s load-bearing simplification, the idea that Claude just returns Brave’s top 10 verbatim with no re-ranking. Architecturally, a keyword search engine with a retrieval database beside it is exactly the kind of stack that could filter or reorder beyond raw Brave rank. I’m not claiming it does. I’m saying the “pure passthrough” assumption can no longer be stated as settled, and the second web-search subprocessor is why.
Dynamic Filtering Is Real, and “No Re-Ranking” Is Contested
Two claims travel welded together in the coverage, and they need separating. The first is dynamic filtering, which Anthropic shipped in February 2026. The web-search tool now writes code to keep only relevant content from a page and discard the rest, mostly for token efficiency. It cleans the page. It is not established that it changes the leaderboard.
The second is the “no re-ranking” claim itself. A June 2026 vendor session repeated that Claude doesn’t re-rank and appears to use Brave’s top 10 results directly, and a firsthand recap of the same event put it more bluntly: no meaningful reshuffling. Profound’s June re-run came after dynamic filtering shipped, so the no-re-ranking shortcut has survived at least one retest of the changed stack.
What no one has published is the test that would settle it: stratified by query intent across commercial, informational, and local, with confidence intervals on every overlap rate, and separating what Claude retrieved from what it actually cited. I’m telling you the standard, and we hold our own claims to it. Anyone telling you it’s settled in either direction is ahead of the evidence.
How Claude Cites Differently From ChatGPT and Gemini
Claude sources the web differently from every other major engine: heavier on reviews and social proof, lighter on journalism, and far less likely to run a search at all.
Claude over-indexes on reviews and social proof. A Yext analysis of 17.2 million AI citations from Q4 2025 found Claude’s reliance on reviews and social sources runs two to four times higher than competing models across every sector measured. By Yext’s count, roughly one in four of Claude’s sources for a restaurant query is a review or social post, against something closer to one in forty for Gemini.

Claude also cites journalism the least. Nieman Lab reporting on Muck Rack’s million-citation dataset found Claude appeared to cite journalistic sources less than any other major model, citing some major newswires a fraction as often as ChatGPT or Gemini do.
And Claude searches far less often than you’d assume. Profound’s own testing, presented at the same June 2026 session, puts Claude’s search-trigger rate at 36.6% of prompts, versus roughly 90 to 95% for ChatGPT. If that rate holds beyond Profound’s prompt set, most Claude answers never touch Brave at all.
One caveat: Yext’s data is from Q4 2025, Muck Rack’s from mid-2025, Profound’s from June 2026. The composite is a sketch drawn across just over a year of a fast-moving system.
The implication for clients inverts the ChatGPT playbook. For Claude specifically, reviews, social proof, and structured reference data may matter more than press hits, and for most queries the model’s trained-in knowledge matters more than anything Brave surfaces in the moment.
Every GEO Stat Is Vendor-Shaped, Including Ours
Every marquee number in GEO research flatters whatever its author sells: the GEO-tooling vendor found Claude tracks Brave, the listings vendor found owned sources win, and even the statistics paper this piece leans on later comes from a measurement vendor whose remedy is, naturally, more measurement. But a serious reader checks each claim against the incentive behind it, and a serious agency says so out loud.
So: Xponent21 sells AI search optimization services. We have a commercial interest in you believing this work is worth doing. The corrected numbers in this piece, the 79.2%, the 64%, the 36.6%, are also Profound’s data, published from a talk at the vendor’s own event. You now know the chain they traveled.
We grew our own Google impressions 168x in 11 months — then lost about 90% of that visibility in early 2026 when we paused publishing. We wrote up the collapse publicly. A single number captured on one day, on three queries, is the last thing I’d build a client strategy on without first-party verification.
The Three Levers of AI Visibility: Memory, Retrieval, Extractability
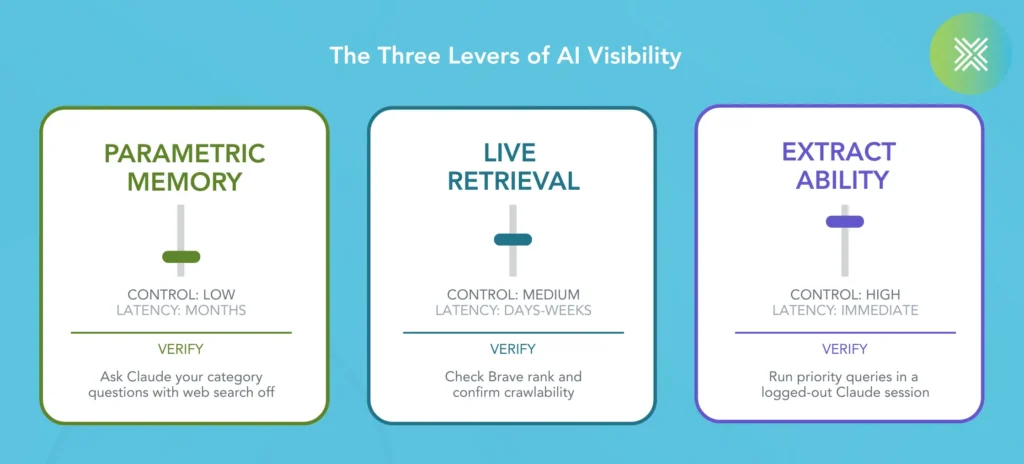
The common playbook’s deeper problem is that it collapses three different things into one. Internally, we separate them into three levers, each with a different control surface, latency, and way to verify. Two of these levers will sound like traditional SEO and brand PR. They are. The framework is telling you which of three separate systems your effort is actually aimed at.
Lever One: Parametric Memory
Control: low and indirect. Latency: months. Verify: ask Claude your category questions with web search turned off.
What Claude knows from training, before it searches anything. This lever decides the answer whenever Claude doesn’t search, roughly two-thirds of prompts in Profound’s June test set.
It is also the slowest lever. You’re trying to change what enough of the web has said about you, consistently enough and for long enough, that Claude carries the association into its answer before it ever runs a search. That work is earned coverage and clean entity signals across sources, and it’s the one thing on this list you can’t move in a quarter.
Lever Two: Live Retrieval
Control: medium. Latency: days to weeks. Verify: check your Brave rank and confirm your pages are actually crawlable.
Whether Brave surfaces you when Claude does search.
Brave’s crawler advertises no distinct user agent, so there is no “allow Bravebot” line to add. The lever you actually pull sits one step upstream, in keeping Googlebot’s access to your pages clean. You’re optimizing the input to the input.
Lever Three: Extractability
Control: high. Latency: immediate. Verify: run your priority queries in a logged-out Claude session and check whether your passage is what gets quoted, not just whether your domain appears.
Whether your content survives the cut and actually gets quoted once you’re in the retrieval set. The dynamic-filtering behavior described earlier gates this lever: a page can rank on Brave and still lose the citation if it isn’t built to be extracted.
The peer-reviewed GEO research is blunt here. Adding statistics, quotations, and citations lifted visibility by up to roughly 40%, while keyword stuffing performed at or below baseline.
That number deserves the same scrutiny I’ve applied to everyone else’s. A 2026 statistical-methods paper measured how much citation visibility fluctuates across Perplexity, SearchGPT, and Gemini when you simply re-run the same queries. The answer: 5 to 7 percentage points of swing is routine. The paper names the GEO study directly, pointing out that without confidence intervals on the original results, you cannot tell how much of a reported improvement is real and how much is measurement wobble. “Up to 40%” is a strong, well-sourced direction. Promising it to a client would outrun the measurement.
The Corrected Claude Playbook
Seven moves, in priority order.
- Check your Brave rank for category terms at brave.com/search. This is the five-minute diagnostic the original advice gets right.
- Protect Googlebot access first, because Brave won’t crawl what Googlebot can’t reach. Audit your robots.txt and firewall rules for overly broad “block unknown bots” settings, and use the noindex directive, not robots.txt, when you deliberately want a page out of the index.
- Match the lever to the query type. “Best,” “top,” and local queries trigger a search, so retrieval work earns its keep there: Brave rank, crawlability, reviews. “How does” and “what is” queries mostly stay in memory, where the only lever in play is what the wider web has said about you over months. Optimizing the wrong lever for the query is effort spent where the system will never look.
- For Claude specifically, put reviews and social proof ahead of press, because Claude over-weights them relative to other engines.
- Write for extraction and filtering. Lead with the answer, add real statistics and named sources, structure for clean headings. Be the chunk Claude keeps, not just the page Brave ranks.
- Write sections that survive being read alone. Name your subject explicitly instead of leaning on pronouns from three paragraphs back, keep one topic per section, and open each section with the claim it exists to make. Anthropic’s own contextual retrieval engineering cut failed retrievals by 49% just by restoring missing context to isolated chunks. Treat this as legibility work. An independent NeurIPS benchmark found content-rewriting tactics alone produce near-zero ranking gains.
- Don’t over-index on one engine. Citations shift substantially month to month, and Claude sources differently from ChatGPT and Gemini. A backend-specific tactic is the most fragile thing you can build on. Especially when the market leader is still in flux.
Even the vendor’s June 2026 re-run isn’t the definitive study this question needs. That study is one we may run.
When we publish first-party numbers on these questions, they’ll come from CARL Intelligence, the AI-visibility tracker we launched out of the CARL ecosystem on June 1, 2026.
The Bottom Line on Optimizing for Claude
Claude is one surface among several, and a hard one to target cleanly, because part of its web-search stack is a subprocessor whose role isn’t public. The durable move is to be worth citing: crawlable, well-reviewed, clearly structured, and known for something specific. It’s the only hedge that survives the next backend change.
And don’t take our numbers on faith either. CARL Intelligence tracks what Claude, ChatGPT, Perplexity, and Google’s AI surfaces are saying about your brand. You can try it free for 90 days and extend to six months with a strategy call. Run your own incognito audit against everything we’ve claimed here.
Optimize for the answer. The index keeps changing. The reasons a system trusts you change much more slowly.
FAQ
- Does Claude use Brave for its web searches in 2026?
- Is Brave the only thing powering Claude’s web search?
- What is turbopuffer?
- Does my Google ranking still matter for showing up in Claude?
- Where does the “86.7% Brave overlap” figure come from, and is it reliable?
- How is optimizing for Claude different from optimizing for ChatGPT?
- What are the three levers of AI visibility?

Isaac Marcuson
Isaac Marcuson is an AI SEO & Content Editor at Xponent21, a digital marketing agency in Richmond, Virginia, focused on AI search optimization. He runs the AI-assisted content systems behind the agency's work and edits what those systems produce. The job makes him a daily student of one question: why language models cite what they cite. Before Xponent21, he spent nearly eight years as a freelance digital strategist in finance, healthcare, e-commerce, and the skilled trades. Each defined expertise its own way. Trust had to be earned in the local dialect. Offline, Isaac reads philosophy, theology, and cognitive science, and walks the James River most days.